Backend Architecture for Import-from-URL (Scalable + Reliable)
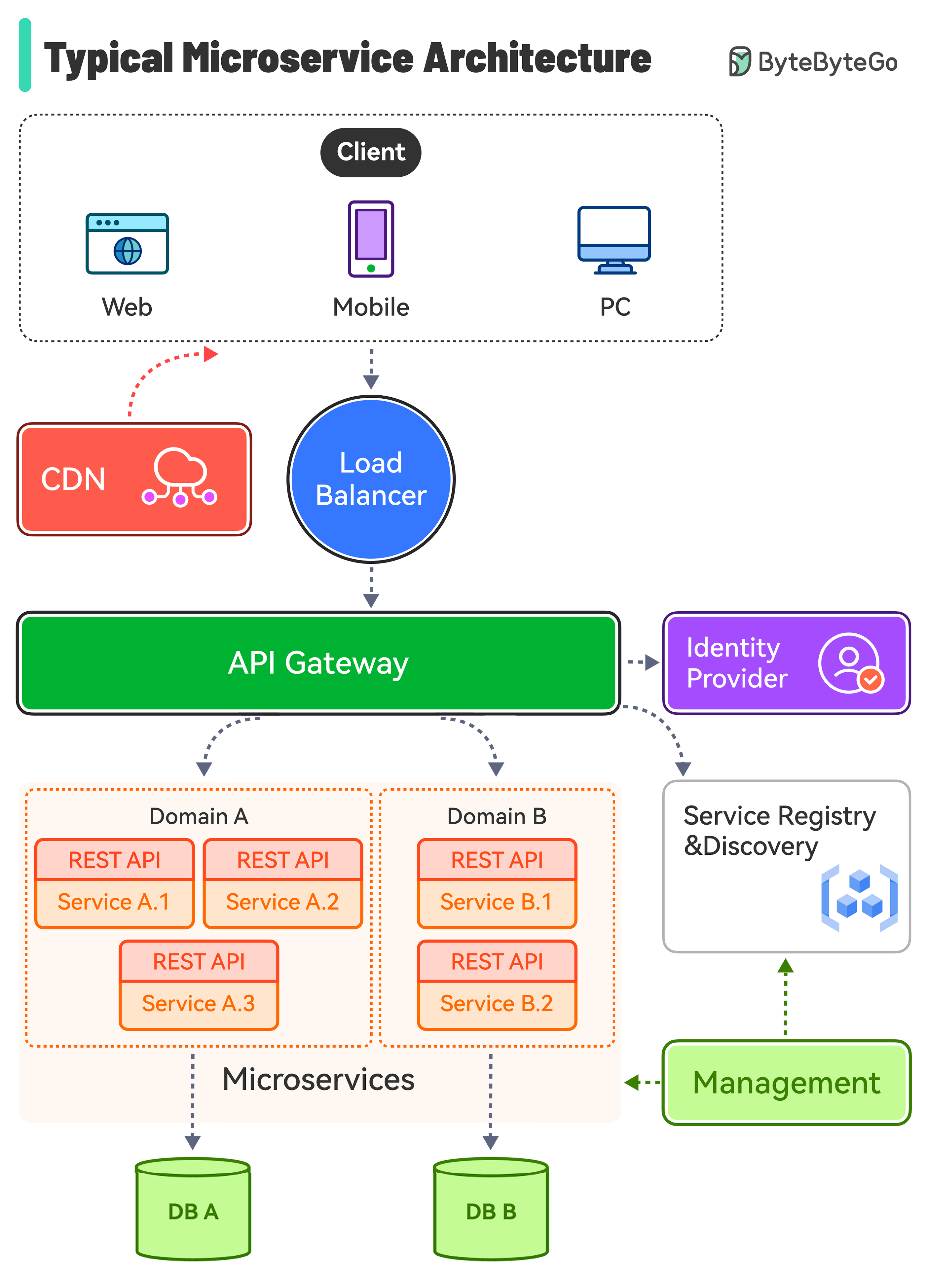
If you're building import-from-URL at scale, the backend is where reliability is won or lost. A robust design needs validation, async processing, retries, and observable status transitions.
Quick answer
A production-grade backend for URL imports usually includes:
- URL validation service
- Async ingestion workers
- Queue + retry policies
- Metadata store + job status model
- Webhook/event delivery pipeline
- Monitoring + alerting
Core backend responsibilities
- Validate and normalize source URLs
- Start ingestion jobs asynchronously
- Persist status and output metadata
- Handle transient failures with retries
- Deliver completion/failure events reliably
- Expose status APIs to clients
Typical service architecture
1) URL validation service
- Syntax + scheme checks
- Host allow/deny rules
- Optional HEAD preflight for content hints
2) Fetch/ingest worker
- Pulls jobs from queue
- Fetches remote media safely
- Applies processing and destination rules
3) Queue + retry policy
- Exponential backoff for transient failures
- Max-attempt controls
- Dead-letter queue for non-recoverable cases
4) Storage + metadata DB
- Output artifact location
- Job status transitions
- Correlation IDs and timestamps
5) Webhook/event pipeline
- Emit status events:
queued,processing,completed,failed - Sign payloads
- Retry delivery with idempotent consumer support
Reliability patterns that matter most
- Idempotency keys for create-job requests
- At-least-once delivery tolerance in webhook consumers
- Dead-letter queues for poison jobs/events
- Structured logs + trace IDs for fast debugging
- SLOs and alerts on failure rate and latency
Security and compliance basics
- Restrict internal network egress paths where possible
- Enforce URL validation and content limits
- Store API credentials in secret managers, not code
- Verify webhook signatures before processing
- Keep audit logs for ingestion events and admin actions
Managed approach with Importly
Using Importly lets you offload:
- Remote media fetch complexity
- Async ingestion orchestration
- Retry/event delivery primitives
You retain control of:
- Product state machine
- Access control/business rules
- UX and downstream domain workflows
Sample payload and event shape
Job create payload (conceptual)
json
Completion webhook (conceptual)
json
Production readiness checklist
- [ ] URL validation and allow/deny policy in place
- [ ] Queue retry/backoff and dead-letter path configured
- [ ] Idempotency for job creation implemented
- [ ] Webhook signature verification implemented
- [ ] Status model documented and tested
- [ ] Alerts for error rate and queue lag enabled
- [ ] Runbook for failed imports documented
FAQ
What fails first in most DIY import backends?
Usually retry logic and event consistency. Teams underestimate transient network issues and duplicate event handling.
Do I need webhooks if I already expose status endpoints?
Yes, in most cases. Webhooks reduce polling overhead and improve responsiveness for async workflows.
What should I benchmark before launch?
Test success rate, p95 completion latency, retry recovery rate, and webhook delivery success on real traffic patterns.